目次
概要
eBPF は extended Berkeley Packet Filter の略。ユーザ空間で作成したプログラムをカーネルに送り込んで、独自の命令セット を持つカーネル内部の仮想マシン(以下VM)上で実行できる機能。eBPF は BPF(Berkeley Packet Filter)と呼ばれる古くからあるパケットフィルタの技術を拡張したもので、パケットフィルタに限らず OS 用途一般に使える。システムに危険を及ぼす可能性のあるコードは、事前のチェックで検出され実行できないようになっています。例えば、ループ処理を含むコードを実行できない等の制約があります。
eBPF のバイトコードを人が直接記述するのは大変なので、C言語やその他言語で簡単に eBPF を扱えるように、BCC(BPF Compiler Collection)と呼ばれるツール群が提供されています。
歴史
eBPF (extended Berkeley Packet Filter)は、Linuxカーネルで使われるプログラミング言語です。eBPFは、Berkeley Packet Filter (BPF)という名前を持つ、古いカーネルプログラミング言語を拡張したものです。BPFは、1980年代にBerkeley Unixで使われるようになりました。eBPFは、Linuxカーネルバージョン3.15から導入されました。
主な用途
eBPFは、パフォーマンス分析、セキュリティ、ネットワークステータスの監視など、さまざまな用途で使われています。eBPFは、カーネル空間とユーザ空間を挟んで動作するため、セキュリティ上の理由からも注目されています。
最近では、eBPFを用いたサービスやツールが、さまざまな用途で普及しています。例えば、DockerやKubernetesでは、eBPFを用いたネットワークプログラミングがサポートされています。また、Linuxカーネルでは、eBPFを用いたセキュリティ機能が導入されていることもあります。
| # | 用途 | 説明 |
| 1 | セキュリティ | すべてのSystemCallを解析し、すべてのネットワーク操作とパケットとソケットレベルのビューと組み合わせることで、システム保護の新しいアプローチを可能にします。SystemCallフィルタリング、ネットワークレベルのフィルタリング、プロセスコンテキストのトレースは、通常、完全に独立したシステムで処理されますが、eBPFは、すべての側面の可視化と制御を組み合わせることで、より多くのコンテキストで動作するセキュリティシステムを、より優れた制御レベルで作成することができます。 |
| 2 | ネットワーク | eBPFはネットワーキングソリューションのあらゆるパケット処理要件に自然に適合します。eBPFのプログラマビリティは、Linuxカーネルのパケット処理コンテキストを離れることなく、プロトコルパーサの追加や、変化する要件に対応した転送ロジックの容易なプログラミングを可能にします。また、JITコンパイラによる効率的な実行により、カーネル内でネイティブにコンパイルされたコードに近い実行性能が得られます。 |
| 3 | トレース&プロファイル | カーネルやユーザーアプリケーションのProbe Point/TracePointにeBPFプログラムをアタッチできるため、アプリケーションやシステム自体のランタイム挙動をより詳細に観測できます。アプリケーション側とシステム側の両方から解析することで、両方のビューを組み合わせることができ、システムパフォーマンス問題のトラブルシューティングのための強力でユニークな洞察を可能にします。高度な統計データ構造により、類似のシステムで一般的に行われているような膨大なサンプリングデータのエクスポートを必要とせず、意味のある可視性データを効率的に抽出することができます。 |
| 4 | Observability & Monitoring | eBPFは、OSが公開する静的な統計情報の代わりに、カスタムメトリックの収集・集約や、幅広いソースに基づく可視性イベントの生成を可能にします。これにより、より多くの情報を観測や、必要な観測データのみの収集、イベントベースのヒストグラムや同様のデータ構造を生成が可能になります。 |
主なプロジェクト
eBPFを用いた主なプロジェクトとして、以下のようなものがあります。
| # | プロジェクト | 説明 |
| 1 | bcc | BPF Compiler Collection (bcc)は、eBPFを用いたパフォーマンス分析やセキュリティツールを作成するためのフレームワークです。bccには、eBPFを用いたプロファイリングやトレーシング、ネットワークステータスの監視など、さまざまなツールが含まれています。 |
| 2 | Cilium | Ciliumは、コンテナorchestrationフレームワークであるKubernetesで使われる、eBPFを用いたネットワークセキュリティプラットフォームです。Ciliumは、Kubernetesクラスタ内のコンテナ間のコミュニケーションをセキュリティ保護するために、eBPFを用いています。 |
| 3 | bpftrace | bpftraceは、eBPFを用いたトレーシングやプロファイリングのためのスクリプト言語です。bpftraceは、カーネルやアプリケーションのパフォーマンスを計測したり、トレースするために使われます。 |
| 4 | Netronome Agilio CX | Netronome Agilio CXは、eBPFを用いたハイパフォーマンスのネットワークアクセラレータです。Agilio CXは、大量のデータを高速で処理するために、eBPFを用いています。 |
| XRP |
これらは、eBPFを用いた主なプロジェクトの一部です。eBPFは、さまざまな分野で使われており、その使われ方はまだまだ拡大していると考えられます。
実行環境
eBPFは、Linuxカーネルのバージョン3.15以降でサポートされています。そのため、3.15以降のカーネルでは、eBPFを使うことができます。
ただし、eBPFを使うには、カーネルがeBPFをサポートしているだけでは不十分です。eBPFを使うには、カーネルにeBPFをサポートするためのモジュールがロードされている必要があります。これらのモジュールは、標準でカーネルに含まれている場合もあれば、カーネルをコンパイルする際に有効にする必要がある場合もあります。
eBPFのアーキテクチャ
アプリケーション開発者は、カーネル内でサンドボックス化されたeBPFプログラムを実行できるようにすることで、OSに実行時に機能を追加することができます。カーネルは、JIT(Just-In-Time)コンパイラと検証エンジンによって、あたかもネイティブにコンパイルされたかのように、eBPFプログラム安全性と実行効率を保証します。これにより、ネットワーク、Observatory、セキュリティなど、さまざまなユースケースをカバーするeBPFベースのプロジェクトが誕生しています。
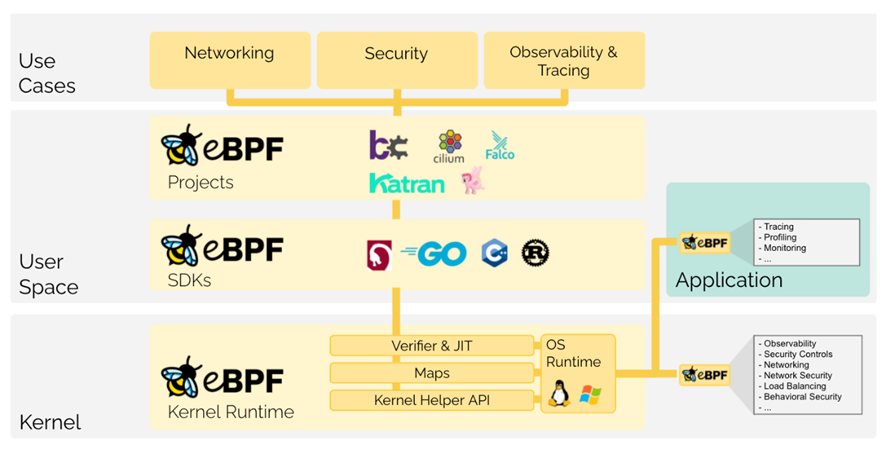
下図はeBPFのアーキテクチャを簡略化したものです。カーネルにロードされる前に、eBPFプログラムは特定の検証され、実行されます。
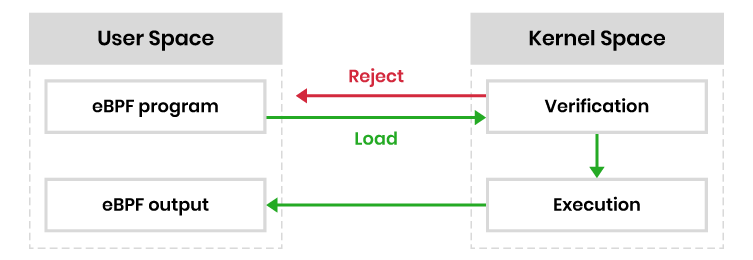
これにより、1万行以上のコードを持つVerifierが一連のチェックを行うことができます。Verifierは、eBPFプログラムがカーネルで実行されたときに通る可能性のある経路を調べ、カーネルのロックアップを引き起こすようなループがなく、プログラムが完了するまで実行されることを確認します。
eBPFは、これらの安全制御を追加することで、Linux Loadable Kernel Modules (LKM)と異なります。
すべてのチェックがクリアされると、eBPFプログラムはカーネルにロード、コンパイルされ、カーネルのコードパスのどこかで通知を待ちます。通知がイベントの形で受信されると、eBPFプログラムがコードパスにロードされます。起動されたバイトコードが実行されます。
eBPFは、プログラマがカーネルのソースコードに追加や変更を加えることなく、Linuxカーネル内で安全にカスタムバイトコードを実行することができます。LKMを完全に置き換えることはできませんが、eBPFプログラムは、カーネルへの脅威を抑えながら、保護されたハードウェアリソースに関連するカスタムコードを導入します。
内部で使われている仕組み
Predefined Hooks
eBPFのプログラムは、トリガーとなるイベントにより実行されます。アプリケーション(またはカーネル)は「Hook point」と呼ばれるフックから呼び出されます。Hook pointはあらかじめ定義されており、ネットワークイベント、システムコール、関数のエントリーおよびエグジット、カーネルトレースポイントなどのイベントを含めることができます。特定の要件に対する定義済みフックがない場合、ユーザーまたはカーネルプローブ(uprobeまたはkprobe)を作成することができます。
Program verification
カーネルは、Hook pointの呼び出しが特定されると、BPFシステムコールを使って、対応するeBPFプログラムをLinuxカーネルにロードします。eBPFプログラムは通常、eBPFライブラリを使用します。プログラムがカーネルにロードされると、安全を確認するために検証されます。検証では、次のような条件が検証されます。
・ プログラムは、特権を持つeBPFプロセスによってのみロードできる(特に指定がない限り)。
・ プログラムがシステムに損害を与えたり、クラッシュしたりしないこと。
・ プログラムは常に完了するまで実行される(無限ループに陥らない)
eBPF Maps
eBPF プログラムは状態を持ち、収集したデータを共有できなければなりません。eBPF マップは、プログラムが様々なデータ構造の情報を取得し、保存することを可能とします。ユーザーは、eBPFプログラムとアプリケーションの両方から、システムコールを介してeBPFマップにアクセスすることができます。
マップの種類には、ハッシュテーブルや配列、リングバッファ、スタックトレース、LRU(least-recently used)、最長接頭辞一致(longest prefix match)などがあります。
Helper calls
eBPF プログラムは、任意にカーネル関数を呼び出すことはできません。これは、eBPFプログラムが互換性を維持し、特定のバージョンのカーネルに束縛されるのを避ける必要があるためです。そのため、eBPFプログラムはヘルパー関数を用いて関数呼び出しを行います。ヘルパー関数はカーネルが提供するAPIであり、簡単に調整することができる。
ヘルパー関数を使うと、乱数の生成、現在の時刻と日付の取得、eBPFマップへのアクセス、転送ロジックとネットワークパケットの操作などを行うことができます。
Function and Tail Calls
これらの呼び出しによって,eBPFのプログラムは構成可能になっています.関数呼び出しは,プログラム中に関数を定義して呼び出すことができる.テールコールは他のeBPFプログラムの実行を可能にする。また、実行コンテキストを変更することができる。
適用方法
bcc
eBPFを実行するためには、C言語で作成したeBPFプログラムをHook pointにアタッチする必要があります。bccとはeBPFプログラムをHook pointにあっちするためのPython/Lua用フレームワークです。C言語で書いたコードをPython/Luaを用いてアタッチし,eBPFで得た情報をログやファイルに出力する部分をbccで行うことができます。bccのGo版にはgobpfというフレームワークもあります。
Hook pointには大きく、カーネル関数をフックするKprobeと、カーネルに用意されているトレース用のtracepointが使用できます。Kprobeとtracepointの違いとして,カーネルバージョンにより関数名が変化しやすいkprobeに比べ、tracepointはカーネルバージョンによる違いが少ないです。その代わり全ての機能に対してtracepointが用意されているわけではありません。基本的にはtracepointを用いて,求めているものが存在しない場合はKprobeを使うのが良いと思います。
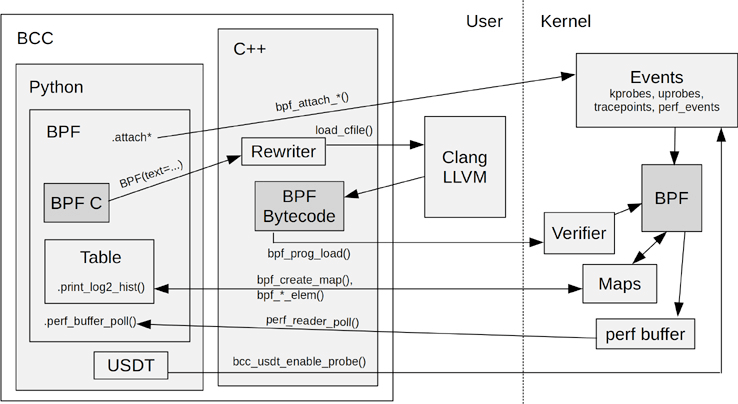
bccの詳細はbcc Reference Guide (googlesource.com)が参考になります。カーネルバージョンごとのサポート機能はbcc/kernel-versions.md at master · iovisor/bcc · GitHubにまとめられています。bccで使えるhelper関数はmanページ(bpf-helpers(7) – Linux manual page (man7.org))にまとまっています。
インストール方法
Ubuntu 20.04ではaptを使ってbccをインストールできますがバージョンが古く、サンプルコード(例:kretprobe)が動かないことがありました。ここではソースからコンパイルすることで最新バージョンをインストールします。
root@ubuntu2:/home/takayuki/repos/bcc/build# sudo apt install -y bison build-essential cmake flex git libedit-dev libllvm12 llvm-12-dev libclang-12-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
takayuki@ubuntu2:~/repos$ git clone https://github.com/iovisor/bcc.git
Cloning into 'bcc'...
remote: Enumerating objects: 27391, done.
remote: Counting objects: 100% (57/57), done.
remote: Compressing objects: 100% (41/41), done.
remote: Total 27391 (delta 23), reused 35 (delta 16), pack-reused 27334
Receiving objects: 100% (27391/27391), 18.37 MiB | 609.00 KiB/s, done.
Resolving deltas: 100% (18047/18047), done.
takayuki@ubuntu2:~/repos$ mkdir bcc/build
takayuki@ubuntu2:~/repos$ cd bcc/build
takayuki@ubuntu2:~/repos/bcc/build$ cmake .. -DCMAKE_PREFIX_PATH=/usr/lib/llvm-12
takayuki@ubuntu2:~/repos/bcc/build$ sudo make install
takayuki@ubuntu2:~/repos/bcc/build$ cmake -DPYTHON_CMD=python3 ..
takayuki@ubuntu2:~/repos/bcc/build$ pushd src/python/
takayuki@ubuntu2:~/repos/bcc/build$ make
takayuki@ubuntu2:~/repos/bcc/build$ sudo make install
takayuki@ubuntu2:~/repos/bcc/build$ popd実行方法
Ubuntu 20.04.1にbcc実行環境を構築してみます。インストール方法はbcc/INSTALL.md at master · iovisor/bcc · GitHubに公式ドキュメントがあります。
sudo apt-get install bpfcc-tools linux-headers-$(uname -r)Hook point
bccではkprobeとtracepointをHook pointとして使用します。カーネルから何かしらの内部状態を取得したいと考えたときに、カーネルのどの関数やTracepointをHook pointとして使用するかを決める必要があります。
kprobeをHookできる関数
kprobeをHookできる関数は/sys/kernel/debug/tracing/available_filter_functionsから取得できます。
takayuki@ubuntu2:~$ sudo cat /sys/kernel/debug/tracing/available_filter_functions|grep bio_|head -5
end_swap_bio_write
end_swap_bio_read
end_bio_bh_io_sync
dio_bio_end_io
dio_bio_completetracepointのHookできる箇所
tracepointはbcc-toolsに含まれるtplist-bpfccコマンドで取得できます。
takayuki@ubuntu2:~$ sudo tplist-bpfcc |grep bio|head -5
block:block_bio_complete
block:block_bio_bounce
block:block_bio_backmerge
block:block_bio_frontmerge
block:block_bio_queueeBPFのC言語制約
eBPFプログラムは一部のC言語の機能が使えません。これらの機能を使おうとしても、Verifierにより実行に失敗します。主な制約として以下のようなものがあります(linux kernel – What is not allowed in restricted C for ebpf? – Stack Overflow参照)。
- 制限なし/可変長のloop
- グローバル変数(グローバル変数が必要な場合、mapで代用)
- 可変長引数関数
- 少数変数
- 構造体を用いた引数(ポインタ渡しは可能)
サンプルコード
attach_kprobe(kprobeを用いたカーネル内の関数へのHook)
attach_kprobeを用いて、カーネル内の関数をHook pointに使用することができます。attach_kprobeのサンプルコードにはbcc/hello_fields.py at master · iovisor/bcc · GitHubが参考になります。
#!/usr/bin/python
#
# This is a Hello World example that formats output as fields.
from bcc import BPF
from bcc.utils import printb
# define BPF program
prog = """
int hello(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
except KeyboardInterrupt:
exit()
printb(b"%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))サンプルコードでは、まずBPFプログラムをloadし、attach_kprobeを用いてcloneシステムコールにアタッチしています。
BPFプログラム内では、bpf_trace_printkに”Hello World!”という文字列を出力しています。
# define BPF program
prog = """
int hello(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""となっているのがeBPFプログラム本体です.pt_regsという型のポインタであるctxという引数をとっていますが,これにはカーネルが現在処理中のものに関する情報が入っています。しかし,その中身はアーキテクチャや対象となるフックポイントなどによっても違うらしいです。bpf_trace_printkはデバッグ用の機能で,タイムスタンプなどの情報と共に,引数に渡したものを/sys/kernel/debug/tracing/trace_pipeへ送ります。以降のpythonコードではwhile文で、trace_pipeの中身をtrace_fields()により参照し、BPFから文字列を受信した場合にがあった場合にprintしています。
hello_field.pyを実行結果を以下に示します。今回用いたUbuntu 20.04ではmacro redefinedのワーニングがでていますが、実行結果への影響はないようで、特に問題なく動いています。
takayuki@ubuntu2:~/bcc$ sudo -E python3 hello_field.py
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from ./include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:80:
include/linux/compiler-clang.h:41:9: warning: '__HAVE_BUILTIN_BSWAP32__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP32__
^
<command line>:4:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP32__ 1
^
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from ./include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:80:
include/linux/compiler-clang.h:42:9: warning: '__HAVE_BUILTIN_BSWAP64__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP64__
^
<command line>:5:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP64__ 1
^
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from ./include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:80:
include/linux/compiler-clang.h:43:9: warning: '__HAVE_BUILTIN_BSWAP16__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP16__
^
<command line>:3:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP16__ 1
^
3 warnings generated.
TIME(s) COMM PID MESSAGE
1533.386090000 cron 753 Hello, World!
1533.401190000 cron 2431 Hello, World!
1533.414180000 sh 2432 Hello, World!
1537.007400000 bash 2365 Hello, World!
1720.162412000 NetworkManager 562 Hello, World!
1810.007684000 systemd 1 Hello, World!
1810.019286000 nm-dispatcher 2437 Hello, World!
Kretprobe(kretprobeを用いたカーネル内の関数exitへのHook)
Kretprobeはカーネル内の関数が実行し終わったタイミングでeBPFプログラムを実行します。そのため、関数の返り値などにアクセスできます。Kprobesと組み合わせることで、関数の中で処理された内容や処理時間、状態遷移を調べることができます。iovisor/bcc/examples/tracing/tcpv4connect.pyの例を示します。
#!/usr/bin/python
#
# tcpv4connect Trace TCP IPv4 connect()s.
# For Linux, uses BCC, eBPF. Embedded C.
#
# USAGE: tcpv4connect [-h] [-t] [-p PID]
#
# This is provided as a basic example of TCP connection & socket tracing.
#
# All IPv4 connection attempts are traced, even if they ultimately fail.
#
# Copyright (c) 2015 Brendan Gregg.
# Licensed under the Apache License, Version 2.0 (the "License")
#
# 15-Oct-2015 Brendan Gregg Created this.
from __future__ import print_function
from bcc import BPF
from bcc.utils import printb
# define BPF program
bpf_text = """
#include <uapi/linux/ptrace.h>
#include <net/sock.h>
#include <bcc/proto.h>
BPF_HASH(currsock, u32, struct sock *);
int kprobe__tcp_v4_connect(struct pt_regs *ctx, struct sock *sk)
{
u32 pid = bpf_get_current_pid_tgid();
// stash the sock ptr for lookup on return
currsock.update(&pid, &sk);
return 0;
};
int kretprobe__tcp_v4_connect(struct pt_regs *ctx)
{
int ret = PT_REGS_RC(ctx);
u32 pid = bpf_get_current_pid_tgid();
struct sock **skpp;
skpp = currsock.lookup(&pid);
if (skpp == 0) {
return 0; // missed entry
}
if (ret != 0) {
// failed to send SYNC packet, may not have populated
// socket __sk_common.{skc_rcv_saddr, ...}
currsock.delete(&pid);
return 0;
}
// pull in details
struct sock *skp = *skpp;
u32 saddr = skp->__sk_common.skc_rcv_saddr;
u32 daddr = skp->__sk_common.skc_daddr;
u16 dport = skp->__sk_common.skc_dport;
// output
bpf_trace_printk("trace_tcp4connect %x %x %d\\n", saddr, daddr, ntohs(dport));
currsock.delete(&pid);
return 0;
}
"""
# initialize BPF
b = BPF(text=bpf_text)
# header
print("%-6s %-12s %-16s %-16s %-4s" % ("PID", "COMM", "SADDR", "DADDR",
"DPORT"))
def inet_ntoa(addr):
dq = b''
for i in range(0, 4):
dq = dq + str(addr & 0xff).encode()
if (i != 3):
dq = dq + b'.'
addr = addr >> 8
return dq
# filter and format output
while 1:
# Read messages from kernel pipe
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
(_tag, saddr_hs, daddr_hs, dport_s) = msg.split(b" ")
except ValueError:
# Ignore messages from other tracers
continue
except KeyboardInterrupt:
exit()
# Ignore messages from other tracers
if _tag.decode() != "trace_tcp4connect":
continue
printb(b"%-6d %-12.12s %-16s %-16s %-4s" % (pid, task,
inet_ntoa(int(saddr_hs, 16)),
inet_ntoa(int(daddr_hs, 16)),
dport_s))まずは関数名の「kprobe__tcp_v4_connect」「kretprobe__tcp_v4_connect」です。BCCでは「イベント名__関数名」という書式で、カーネル内部の任意の関数のイベントをフックして処理を追加できるようになっています。このタイプで記述できるイベントは「kprobes」と「kretprobes」の2種類です。前者が関数が呼び出される前に実行されるイベントで、後者が関数から戻る時に実行されるイベントです。
今回だと「kprobe__tcp_v4_connect」「kretprobe__tcp_v4_connect」という名前であるため、TCP接続のためのカーネル関数「tcp_v4_connect()」の呼び出し時と終了時に指定したコードが実行されることになります。
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len);kprobe/kretprobesでは必ずBPFコンテキストのレジスターを保存する「struct pt_regs *ctx」を第一引数として指定します。使用しない場合には「void *」としています。また、ctxのあとに引数を追加することで、対象関数の引数を任意の数分渡すことができます。kprobe__tcp_v4_connectでは、tcp_v4_connectの一つ目の引数のstruct sock *skを、引数としています。kprobe__tcp_v4_connectでは、独自に定義したハッシュテーブル(BPF_HASH)のcurrsockにプロセスIDをキーとしてsocket構造体を登録しています。
BPF_HASH(currsock, u32, struct sock *);
int kprobe__tcp_v4_connect(struct pt_regs *ctx, struct sock *sk)
{
u32 pid = bpf_get_current_pid_tgid();
// stash the sock ptr for lookup on return
currsock.update(&pid, &sk);
return 0;
};BPF_HASHの更新、参照はupdateとlookupにより行います。eBPFはload時にlookup結果のNullチェックの有無の検証を行うため、lookupを呼出し後にNULLチェックを行う必要があります。もし、NULLチェックがない場合、検証時にmap_value_or_nullエラーがおこり、eBPFプログラムのloadに失敗します。
BPF_HASHやupdate、lookupは以下のSyntaxで使用します。詳細はbcc Reference Guide (googlesource.com)で確認できます。
Syntax: BPF_HASH(name [, key_type [, leaf_type [, size]]])
Syntax: *val map.lookup(&key)
Syntax: map.update(&key, &val)tcp_v4_connect終了時には、プロセスIDからsocket構造体を取得・解析し、bpf_trace_printkを用いてpythonアプリに解析結果を通知しています。
int kretprobe__tcp_v4_connect(struct pt_regs *ctx)
{
int ret = PT_REGS_RC(ctx);
u32 pid = bpf_get_current_pid_tgid();
struct sock **skpp;
skpp = currsock.lookup(&pid);
if (skpp == 0) {
return 0; // missed entry
}
if (ret != 0) {
// failed to send SYNC packet, may not have populated
// socket __sk_common.{skc_rcv_saddr, ...}
currsock.delete(&pid);
return 0;
}
// pull in details
struct sock *skp = *skpp;
u32 saddr = skp->__sk_common.skc_rcv_saddr;
u32 daddr = skp->__sk_common.skc_daddr;
u16 dport = skp->__sk_common.skc_dport;
// output
bpf_trace_printk("trace_tcp4connect %x %x %d\\n", saddr, daddr, ntohs(dport));
currsock.delete(&pid);
return 0;
}tcpv4connect.pyを実行し、別コンソールから適当なtcpコネクションを接続します。
takayuki@ubuntu2:~$ curl -4 example.comtcpv4connect.pyの実行結果に、eBPFで取得したTCPコネクションの情報が出力されました。
takayuki@ubuntu2:~/bcc$ sudo -E python3 tcpv4connect.py
PID COMM SADDR DADDR DPORT
5778 curl 10.0.3.15 93.184.216.34 80 tracepointへのHook
tracepointにHookをする場合は、kprobeやkretprobeのようにカーネル関数を指定するのではなく、tracepointを指定します。以下のコードははkprobe用のコードをtracepointように変更しています。
#!/usr/bin/python
from bcc import BPF
from bcc.utils import printb
# define BPF program
bpf_text= """
TRACEPOINT_PROBE(syscalls,sys_enter_clone) {
bpf_trace_printk("%d",args->parent_tidptr);
return 0;
}
"""
b = BPF(text=bpf_text)
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
except KeyboardInterrupt:
exit()
printb(b"%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))tracepointにHookを入れる場合、TRACEPOINT_PROBEを用います。実行例は以下のとおりです。
takayuki@ubuntu2:~/bcc$ sudo -E python3 tracepoint.py
3292.921102000 bash 1434 0
3300.126525000 bash 1434 0関数の処理時間を計測して出力する
カーネル関数で呼び出しごとにどれだけ処理がかかったがわかれば便利です。ここではkprobeとkretprobeを用いてtcpv4_connect関数の処理時間を計測するtcpv4connect_lat.pyを作成します。
#!/usr/bin/python
from __future__ import print_function
from bcc import BPF
from bcc.utils import printb
# define BPF program
bpf_text = """
#include <uapi/linux/ptrace.h>
#include <net/sock.h>
//#include <bcc/proto.h>
BPF_HASH(starttime_list, /* PID */u32, /* Start time */u64);
int kprobe__tcp_v4_connect(struct pt_regs *ctx, struct sock *sk)
{
u32 pid = bpf_get_current_pid_tgid();
u64 start = bpf_ktime_get_ns();
starttime_list.update(&pid, &start);
return 0;
};
int kretprobe__tcp_v4_connect(struct pt_regs *ctx, struct sock *sk)
{
u32 pid = bpf_get_current_pid_tgid();
u64 *start = starttime_list.lookup(&pid);
if (start == 0) {
bpf_trace_printk("trace_tcp4connect failed to get start time\\n");
return 0; // missed entry
}
u64 exectime = bpf_ktime_get_ns() - *start;
u64 exectime_us = exectime / 1000;
// output
bpf_trace_printk("trace_tcp4connect exectime: %ld ns(%d us)\\n", exectime, exectime_us);
starttime_list.delete(&pid);
return 0;
}
"""
# initialize BPF
b = BPF(text=bpf_text)
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
except KeyboardInterrupt:
exit()
printb(b"%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))kprobe__tcp_v4_connectでbpf_ktime_get_nsを用いて開始時間を記録し、kretprobe__tcp_v4_connectで完了時間と開始時間の差分を計算し、実行時間を出力します。開始時間と完了時間の対応付けはPIDを使用します。
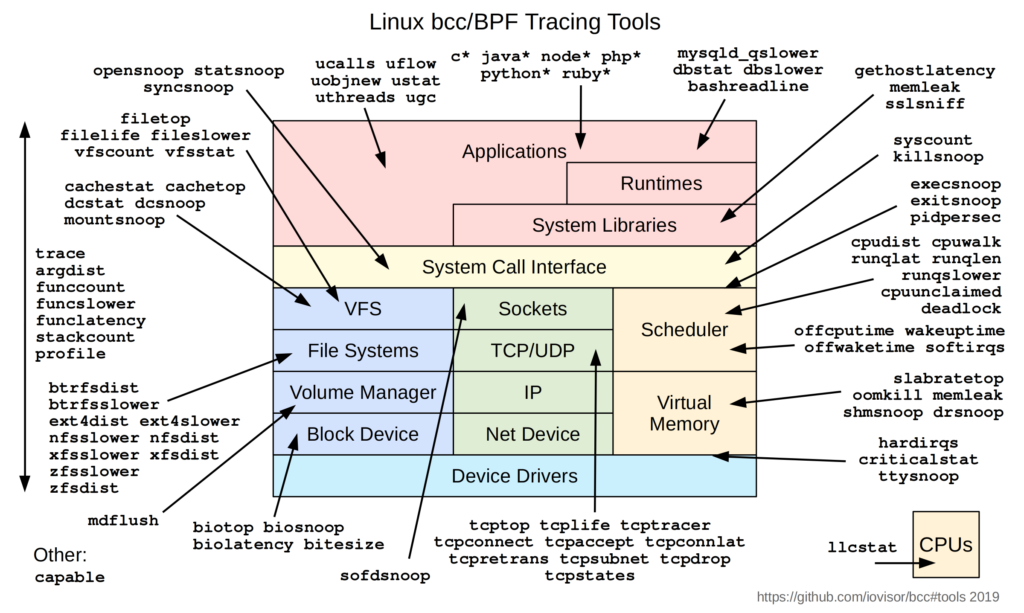
ツール
eBPFでユーザスペースのトレース方法として最も簡単な方法は、bccかbpftraceなどのツールを使う方法です[4]。これらのツールは多くの商用製品でも使用されています。
| # | ツール | 説明 | 可視化方法 | Bcc以前 |
| 1 | execsnoop | 新プロセス | テーブル | |
| 2 | opensnoop | オープンファイル | テーブル | |
| 3 | ext4slower | Filesystem I/O | テーブル | |
| 4 | biolatency | Disk I/Oレイテンシ | Heat map | iostat -xz 1 |
| 5 | biosnoop | イベントごとのDisk IO | テーブル、Offset heat map | |
| 6 | cachestat | ファイルシステムキャッシュ | Line charts | |
| 7 | tcplife | TCPコネクション | テーブル、分布図 | |
| 8 | tcpretrans | TCP再送 | テーブル | |
| 9 | runqlat | CPUスケジューラのレイテンシ | Heat map | |
| 10 | profile | CPUのプロファイル | Flame graph | top |
eBPFで使えるツールの知覧はGitHub – iovisor/bcc: BCC – Tools for BPF-based Linux IO analysis, networking, monitoring, and more にまとめられています。
参考文献
- eBPF入門 (zenn.dev)
- Linux eBPFトレーシング技術の概論とツール実装 – ゆううきブログ (yuuk.io)
- bcc Reference Guide (googlesource.com)
- bcc/kernel-versions.md at master · iovisor/bcc · GitHub
- eBPF – Introduction, Tutorials & Community Resources
- BPF and XDP Reference Guide — Cilium 1.13.90 documentation
- eBPF の紹介 – Qiita
- “XRP: In-Kernel Storage Functions with eBPF,” https://www.usenix.org/conference/osdi22/presentation/zhong
- How To Add eBPF Observability To Your Product (brendangregg.com)
- eBPF Explained: Use Cases, Concepts, and Architecture | Tigera